graph LR;
A1[Running Mode] --> local[fa:fa-laptop local];
local --> l1[local 1: executors number = 1];
local --> ln[local N: executors number = N];
local --> lm[local *: executors number = number of CPU cores];
A1 --> s[fa:fa-server Standalone];
s --> sc[Driver in client, spark-submit];
s --> sm[Driver in Master, spark-shell];
A1 --> y[fa:fa-server YARN];
y --> yc[Yarn Client];
y --> yt[Yarn Cluster];
1.1 Local
Spark runs on local host and does not involve other hosts and components.
- local, 1 executor
- local[N], N executor
- local[*], N executor (while N = number of CPU cores, this is the default mode)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
[root@hadoop001 ~]# jps
26609 Jps
[root@hadoop001 ~]#
[root@hadoop001 ~]# spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[*] \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.2.1.jar 10
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/spark-3.2.1-bin-hadoop2.7/jars/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
22/06/06 12:01:05 INFO spark.SparkContext: Running Spark version 3.2.1
22/06/06 12:01:05 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/06/06 12:01:05 INFO resource.ResourceUtils: ==============================================================
22/06/06 12:01:05 INFO resource.ResourceUtils: No custom resources configured for spark.driver.
22/06/06 12:01:05 INFO resource.ResourceUtils: ==============================================================
22/06/06 12:01:05 INFO spark.SparkContext: Submitted application: Spark Pi
22/06/06 12:01:05 INFO resource.ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 1024, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
22/06/06 12:01:05 INFO resource.ResourceProfile: Limiting resource is cpu
22/06/06 12:01:05 INFO resource.ResourceProfileManager: Added ResourceProfile id: 0
22/06/06 12:01:05 INFO spark.SecurityManager: Changing view acls to: root
22/06/06 12:01:05 INFO spark.SecurityManager: Changing modify acls to: root
22/06/06 12:01:05 INFO spark.SecurityManager: Changing view acls groups to:
22/06/06 12:01:05 INFO spark.SecurityManager: Changing modify acls groups to:
22/06/06 12:01:05 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
22/06/06 12:01:06 INFO util.Utils: Successfully started service 'sparkDriver' on port 38921.
22/06/06 12:01:06 INFO spark.SparkEnv: Registering MapOutputTracker
22/06/06 12:01:06 INFO spark.SparkEnv: Registering BlockManagerMaster
22/06/06 12:01:06 INFO storage.BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
22/06/06 12:01:06 INFO storage.BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
22/06/06 12:01:06 INFO spark.SparkEnv: Registering BlockManagerMasterHeartbeat
22/06/06 12:01:06 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-fe8d55c9-61b8-4535-80cf-7cdf26fb0abd
22/06/06 12:01:06 INFO memory.MemoryStore: MemoryStore started with capacity 366.3 MiB
22/06/06 12:01:06 INFO spark.SparkEnv: Registering OutputCommitCoordinator
22/06/06 12:01:06 INFO util.log: Logging initialized @3141ms to org.sparkproject.jetty.util.log.Slf4jLog
22/06/06 12:01:06 INFO server.Server: jetty-9.4.43.v20210629; built: 2021-06-30T11:07:22.254Z; git: 526006ecfa3af7f1a27ef3a288e2bef7ea9dd7e8; jvm 1.8.0_231-b11
22/06/06 12:01:06 INFO server.Server: Started @3261ms
22/06/06 12:01:06 INFO server.AbstractConnector: Started ServerConnector@51745f40{HTTP/1.1, (http/1.1)}{hadoop001:4040}
22/06/06 12:01:06 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
22/06/06 12:01:06 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@23eee4b8{/jobs,null,AVAILABLE,@Spark}
22/06/06 12:01:06 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@757529a4{/jobs/json,null,AVAILABLE,@Spark}
...
22/06/06 12:01:06 INFO ui.SparkUI: Bound SparkUI to hadoop001, and started at http://hadoop001:4040
22/06/06 12:01:06 INFO spark.SparkContext: Added JAR file:/opt/module/spark-3.2.1-bin-hadoop2.7/examples/jars/spark-examples_2.12-3.2.1.jar at spark://hadoop001:38921/jars/spark-examples_2.12-3.2.1.jar with timestamp 1654488065067
22/06/06 12:01:06 INFO executor.Executor: Starting executor ID driver on host hadoop001
22/06/06 12:01:06 INFO executor.Executor: Fetching spark://hadoop001:38921/jars/spark-examples_2.12-3.2.1.jar with timestamp 1654488065067
22/06/06 12:01:07 INFO client.TransportClientFactory: Successfully created connection to hadoop001/172.17.0.16:38921 after 49 ms (0 ms spent in bootstraps)
22/06/06 12:01:07 INFO util.Utils: Fetching spark://hadoop001:38921/jars/spark-examples_2.12-3.2.1.jar to /tmp/spark-263525b2-227f-47ad-a3cb-dd6dec0838fe/userFiles-3a1c6f44-348c-4a92-9a84-2f001d4c5975/fetchFileTemp6564314709458696631.tmp
22/06/06 12:01:07 INFO executor.Executor: Adding file:/tmp/spark-263525b2-227f-47ad-a3cb-dd6dec0838fe/userFiles-3a1c6f44-348c-4a92-9a84-2f001d4c5975/spark-examples_2.12-3.2.1.jar to class loader
22/06/06 12:01:07 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 42199.
22/06/06 12:01:07 INFO netty.NettyBlockTransferService: Server created on hadoop001:42199
22/06/06 12:01:07 INFO storage.BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
22/06/06 12:01:07 INFO storage.BlockManagerMaster: Registering BlockManager BlockManagerId(driver, hadoop001, 42199, None)
22/06/06 12:01:07 INFO storage.BlockManagerMasterEndpoint: Registering block manager hadoop001:42199 with 366.3 MiB RAM, BlockManagerId(driver, hadoop001, 42199, None)
22/06/06 12:01:07 INFO storage.BlockManagerMaster: Registered BlockManager BlockManagerId(driver, hadoop001, 42199, None)
22/06/06 12:01:07 INFO storage.BlockManager: Initialized BlockManager: BlockManagerId(driver, hadoop001, 42199, None)
22/06/06 12:01:07 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@116a2108{/metrics/json,null,AVAILABLE,@Spark}
22/06/06 12:01:08 INFO spark.SparkContext: Starting job: reduce at SparkPi.scala:38
22/06/06 12:01:08 INFO scheduler.DAGScheduler: Got job 0 (reduce at SparkPi.scala:38) with 10 output partitions
22/06/06 12:01:08 INFO scheduler.DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:38)
22/06/06 12:01:08 INFO scheduler.DAGScheduler: Parents of final stage: List()
22/06/06 12:01:08 INFO scheduler.DAGScheduler: Missing parents: List()
22/06/06 12:01:08 INFO scheduler.DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has no missing parents
22/06/06 12:01:08 INFO memory.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 4.0 KiB, free 366.3 MiB)
22/06/06 12:01:08 INFO memory.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 2.3 KiB, free 366.3 MiB)
22/06/06 12:01:08 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on hadoop001:42199 (size: 2.3 KiB, free: 366.3 MiB)
22/06/06 12:01:08 INFO spark.SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1478
22/06/06 12:01:08 INFO scheduler.DAGScheduler: Submitting 10 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34) (first 15 tasks are for partitions Vector(0, 1, 2, 3, 4, 5, 6, 7, 8, 9))
22/06/06 12:01:08 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 10 tasks resource profile 0
22/06/06 12:01:08 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0) (hadoop001, executor driver, partition 0, PROCESS_LOCAL, 4578 bytes) taskResourceAssignments Map()
22/06/06 12:01:08 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1) (hadoop001, executor driver, partition 1, PROCESS_LOCAL, 4578 bytes) taskResourceAssignments Map()
22/06/06 12:01:08 INFO executor.Executor: Running task 0.0 in stage 0.0 (TID 0)
22/06/06 12:01:08 INFO executor.Executor: Running task 1.0 in stage 0.0 (TID 1)
22/06/06 12:01:09 INFO executor.Executor: Finished task 1.0 in stage 0.0 (TID 1). 1000 bytes result sent to driver
22/06/06 12:01:09 INFO executor.Executor: Finished task 0.0 in stage 0.0 (TID 0). 1000 bytes result sent to driver
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2) (hadoop001, executor driver, partition 2, PROCESS_LOCAL, 4578 bytes) taskResourceAssignments Map()
22/06/06 12:01:09 INFO executor.Executor: Running task 2.0 in stage 0.0 (TID 2)
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3) (hadoop001, executor driver, partition 3, PROCESS_LOCAL, 4578 bytes) taskResourceAssignments Map()
22/06/06 12:01:09 INFO executor.Executor: Running task 3.0 in stage 0.0 (TID 3)
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 722 ms on hadoop001 (executor driver) (1/10)
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 778 ms on hadoop001 (executor driver) (2/10)
22/06/06 12:01:09 INFO executor.Executor: Finished task 2.0 in stage 0.0 (TID 2). 957 bytes result sent to driver
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Starting task 4.0 in stage 0.0 (TID 4) (hadoop001, executor driver, partition 4, PROCESS_LOCAL, 4578 bytes) taskResourceAssignments Map()
22/06/06 12:01:09 INFO executor.Executor: Running task 4.0 in stage 0.0 (TID 4)
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 104 ms on hadoop001 (executor driver) (3/10)
22/06/06 12:01:09 INFO executor.Executor: Finished task 3.0 in stage 0.0 (TID 3). 957 bytes result sent to driver
22/06/06 12:01:09 INFO executor.Executor: Finished task 4.0 in stage 0.0 (TID 4). 957 bytes result sent to driver
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Starting task 5.0 in stage 0.0 (TID 5) (hadoop001, executor driver, partition 5, PROCESS_LOCAL, 4578 bytes) taskResourceAssignments Map()
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Starting task 6.0 in stage 0.0 (TID 6) (hadoop001, executor driver, partition 6, PROCESS_LOCAL, 4578 bytes) taskResourceAssignments Map()
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Finished task 4.0 in stage 0.0 (TID 4) in 52 ms on hadoop001 (executor driver) (4/10)
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 122 ms on hadoop001 (executor driver) (5/10)
22/06/06 12:01:09 INFO executor.Executor: Running task 5.0 in stage 0.0 (TID 5)
22/06/06 12:01:09 INFO executor.Executor: Running task 6.0 in stage 0.0 (TID 6)
22/06/06 12:01:09 INFO executor.Executor: Finished task 5.0 in stage 0.0 (TID 5). 957 bytes result sent to driver
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Starting task 7.0 in stage 0.0 (TID 7) (hadoop001, executor driver, partition 7, PROCESS_LOCAL, 4578 bytes) taskResourceAssignments Map()
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Finished task 5.0 in stage 0.0 (TID 5) in 37 ms on hadoop001 (executor driver) (6/10)
22/06/06 12:01:09 INFO executor.Executor: Running task 7.0 in stage 0.0 (TID 7)
22/06/06 12:01:09 INFO executor.Executor: Finished task 6.0 in stage 0.0 (TID 6). 957 bytes result sent to driver
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Starting task 8.0 in stage 0.0 (TID 8) (hadoop001, executor driver, partition 8, PROCESS_LOCAL, 4578 bytes) taskResourceAssignments Map()
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Finished task 6.0 in stage 0.0 (TID 6) in 76 ms on hadoop001 (executor driver) (7/10)
22/06/06 12:01:09 INFO executor.Executor: Running task 8.0 in stage 0.0 (TID 8)
22/06/06 12:01:09 INFO executor.Executor: Finished task 7.0 in stage 0.0 (TID 7). 957 bytes result sent to driver
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Starting task 9.0 in stage 0.0 (TID 9) (hadoop001, executor driver, partition 9, PROCESS_LOCAL, 4578 bytes) taskResourceAssignments Map()
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Finished task 7.0 in stage 0.0 (TID 7) in 68 ms on hadoop001 (executor driver) (8/10)
22/06/06 12:01:09 INFO executor.Executor: Running task 9.0 in stage 0.0 (TID 9)
22/06/06 12:01:09 INFO executor.Executor: Finished task 8.0 in stage 0.0 (TID 8). 957 bytes result sent to driver
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Finished task 8.0 in stage 0.0 (TID 8) in 52 ms on hadoop001 (executor driver) (9/10)
22/06/06 12:01:09 INFO executor.Executor: Finished task 9.0 in stage 0.0 (TID 9). 957 bytes result sent to driver
22/06/06 12:01:09 INFO scheduler.TaskSetManager: Finished task 9.0 in stage 0.0 (TID 9) in 39 ms on hadoop001 (executor driver) (10/10)
22/06/06 12:01:09 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 1.313 s
22/06/06 12:01:09 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
22/06/06 12:01:09 INFO scheduler.DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
22/06/06 12:01:09 INFO scheduler.TaskSchedulerImpl: Killing all running tasks in stage 0: Stage finished
22/06/06 12:01:09 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 1.562337 s
Pi is roughly 3.1412871412871413
22/06/06 12:01:09 INFO server.AbstractConnector: Stopped Spark@51745f40{HTTP/1.1, (http/1.1)}{hadoop001:4040}
22/06/06 12:01:09 INFO ui.SparkUI: Stopped Spark web UI at http://hadoop001:4040
22/06/06 12:01:09 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
22/06/06 12:01:09 INFO memory.MemoryStore: MemoryStore cleared
22/06/06 12:01:09 INFO storage.BlockManager: BlockManager stopped
22/06/06 12:01:09 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
22/06/06 12:01:09 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
22/06/06 12:01:09 INFO spark.SparkContext: Successfully stopped SparkContext
22/06/06 12:01:09 INFO util.ShutdownHookManager: Shutdown hook called
22/06/06 12:01:09 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-263525b2-227f-47ad-a3cb-dd6dec0838fe
22/06/06 12:01:09 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-d7f3cd11-033f-4518-9019-b33399efee9c
1.2 Standalone
This mode deploys spark on a cluster, but does not rely on any other components such as zookeeper or HDFS.
start all spark services:
1
2
3
4
5
6
7
8
9
[root@hadoop001 spark-3.2.1-bin-hadoop2.7]# ./sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark-3.2.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop001.out
hadoop003: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-3.2.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop003.out
hadoop002: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-3.2.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop002.out
hadoop001: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-3.2.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop001.out
[root@hadoop001 spark-3.2.1-bin-hadoop2.7]# jps
32316 Worker
32190 Master
32446 Jps
1
2
3
[root@hadoop002 ~]# jps
27426 Jps
22632 Worker
1
2
3
[root@hadoop003 ~]# jps
15604 Jps
15451 Worker
1.3 Yarn
This mode rely on Hadoop and YARN resource manager, you should launch hdfs and yarn before submit a spark job.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
[root@hadoop001 ~]# jps
11584 Jps
721 DataNode
596 NameNode
935 JournalNode
1148 DFSZKFailoverController
32062 QuorumPeerMain
334 NodeManager
[root@hadoop001 ~]# spark-submit \
--master yarn \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
/opt/module/spark-3.2.1-bin-hadoop2.7/examples/jars/spark-examples_2.12-3.2.1.jar 10
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/spark-3.2.1-bin-hadoop2.7/jars/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
22/06/06 15:39:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/06/06 15:39:44 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
22/06/06 15:39:44 INFO yarn.Client: Requesting a new application from cluster with 3 NodeManagers
22/06/06 15:39:45 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
22/06/06 15:39:45 INFO yarn.Client: Will allocate AM container, with 1408 MB memory including 384 MB overhead
22/06/06 15:39:45 INFO yarn.Client: Setting up container launch context for our AM
22/06/06 15:39:45 INFO yarn.Client: Setting up the launch environment for our AM container
22/06/06 15:39:45 INFO yarn.Client: Preparing resources for our AM container
22/06/06 15:39:45 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
22/06/06 15:39:47 INFO yarn.Client: Uploading resource file:/tmp/spark-92dd37a5-03cf-43d1-943d-2d6967f9eae6/__spark_libs__1367667354465436050.zip -> hdfs://ns/user/root/.sparkStaging/application_1654489243242_0004/__spark_libs__1367667354465436050.zip
22/06/06 15:39:51 INFO yarn.Client: Uploading resource file:/opt/module/spark-3.2.1-bin-hadoop2.7/examples/jars/spark-examples_2.12-3.2.1.jar -> hdfs://ns/user/root/.sparkStaging/application_1654489243242_0004/spark-examples_2.12-3.2.1.jar
22/06/06 15:39:51 INFO yarn.Client: Uploading resource file:/tmp/spark-92dd37a5-03cf-43d1-943d-2d6967f9eae6/__spark_conf__9127586246596678973.zip -> hdfs://ns/user/root/.sparkStaging/application_1654489243242_0004/__spark_conf__.zip
22/06/06 15:39:51 INFO spark.SecurityManager: Changing view acls to: root
22/06/06 15:39:51 INFO spark.SecurityManager: Changing modify acls to: root
22/06/06 15:39:51 INFO spark.SecurityManager: Changing view acls groups to:
22/06/06 15:39:51 INFO spark.SecurityManager: Changing modify acls groups to:
22/06/06 15:39:51 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
22/06/06 15:39:51 INFO yarn.Client: Submitting application application_1654489243242_0004 to ResourceManager
22/06/06 15:39:51 INFO impl.YarnClientImpl: Submitted application application_1654489243242_0004
22/06/06 15:39:52 INFO yarn.Client: Application report for application_1654489243242_0004 (state: ACCEPTED)
22/06/06 15:39:52 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1654501191680
final status: UNDEFINED
tracking URL: http://hadoop003:8088/proxy/application_1654489243242_0004/
user: root
22/06/06 15:39:53 INFO yarn.Client: Application report for application_1654489243242_0004 (state: ACCEPTED)
22/06/06 15:39:54 INFO yarn.Client: Application report for application_1654489243242_0004 (state: ACCEPTED)
22/06/06 15:39:55 INFO yarn.Client: Application report for application_1654489243242_0004 (state: ACCEPTED)
22/06/06 15:39:56 INFO yarn.Client: Application report for application_1654489243242_0004 (state: ACCEPTED)
22/06/06 15:39:57 INFO yarn.Client: Application report for application_1654489243242_0004 (state: ACCEPTED)
22/06/06 15:39:58 INFO yarn.Client: Application report for application_1654489243242_0004 (state: ACCEPTED)
22/06/06 15:39:59 INFO yarn.Client: Application report for application_1654489243242_0004 (state: ACCEPTED)
22/06/06 15:40:00 INFO yarn.Client: Application report for application_1654489243242_0004 (state: RUNNING)
22/06/06 15:40:00 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: hadoop003
ApplicationMaster RPC port: 40407
queue: default
start time: 1654501191680
final status: UNDEFINED
tracking URL: http://hadoop003:8088/proxy/application_1654489243242_0004/
user: root
22/06/06 15:40:01 INFO yarn.Client: Application report for application_1654489243242_0004 (state: RUNNING)
22/06/06 15:40:02 INFO yarn.Client: Application report for application_1654489243242_0004 (state: RUNNING)
22/06/06 15:40:04 INFO yarn.Client: Application report for application_1654489243242_0004 (state: RUNNING)
22/06/06 15:40:05 INFO yarn.Client: Application report for application_1654489243242_0004 (state: RUNNING)
22/06/06 15:40:06 INFO yarn.Client: Application report for application_1654489243242_0004 (state: RUNNING)
22/06/06 15:40:07 INFO yarn.Client: Application report for application_1654489243242_0004 (state: RUNNING)
22/06/06 15:40:08 INFO yarn.Client: Application report for application_1654489243242_0004 (state: RUNNING)
22/06/06 15:40:09 INFO yarn.Client: Application report for application_1654489243242_0004 (state: RUNNING)
22/06/06 15:40:10 INFO yarn.Client: Application report for application_1654489243242_0004 (state: RUNNING)
22/06/06 15:40:11 INFO yarn.Client: Application report for application_1654489243242_0004 (state: RUNNING)
22/06/06 15:40:12 INFO yarn.Client: Application report for application_1654489243242_0004 (state: RUNNING)
22/06/06 15:40:13 INFO yarn.Client: Application report for application_1654489243242_0004 (state: FINISHED)
22/06/06 15:40:13 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: hadoop003
ApplicationMaster RPC port: 40407
queue: default
start time: 1654501191680
final status: SUCCEEDED
tracking URL: http://hadoop003:8088/proxy/application_1654489243242_0004/
user: root
22/06/06 15:40:13 INFO util.ShutdownHookManager: Shutdown hook called
22/06/06 15:40:13 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-a5d36c98-3308-4dd7-a435-078bee415127
22/06/06 15:40:13 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-92dd37a5-03cf-43d1-943d-2d6967f9eae6
[root@hadoop001 ~]#
open the tracking URL in browser:
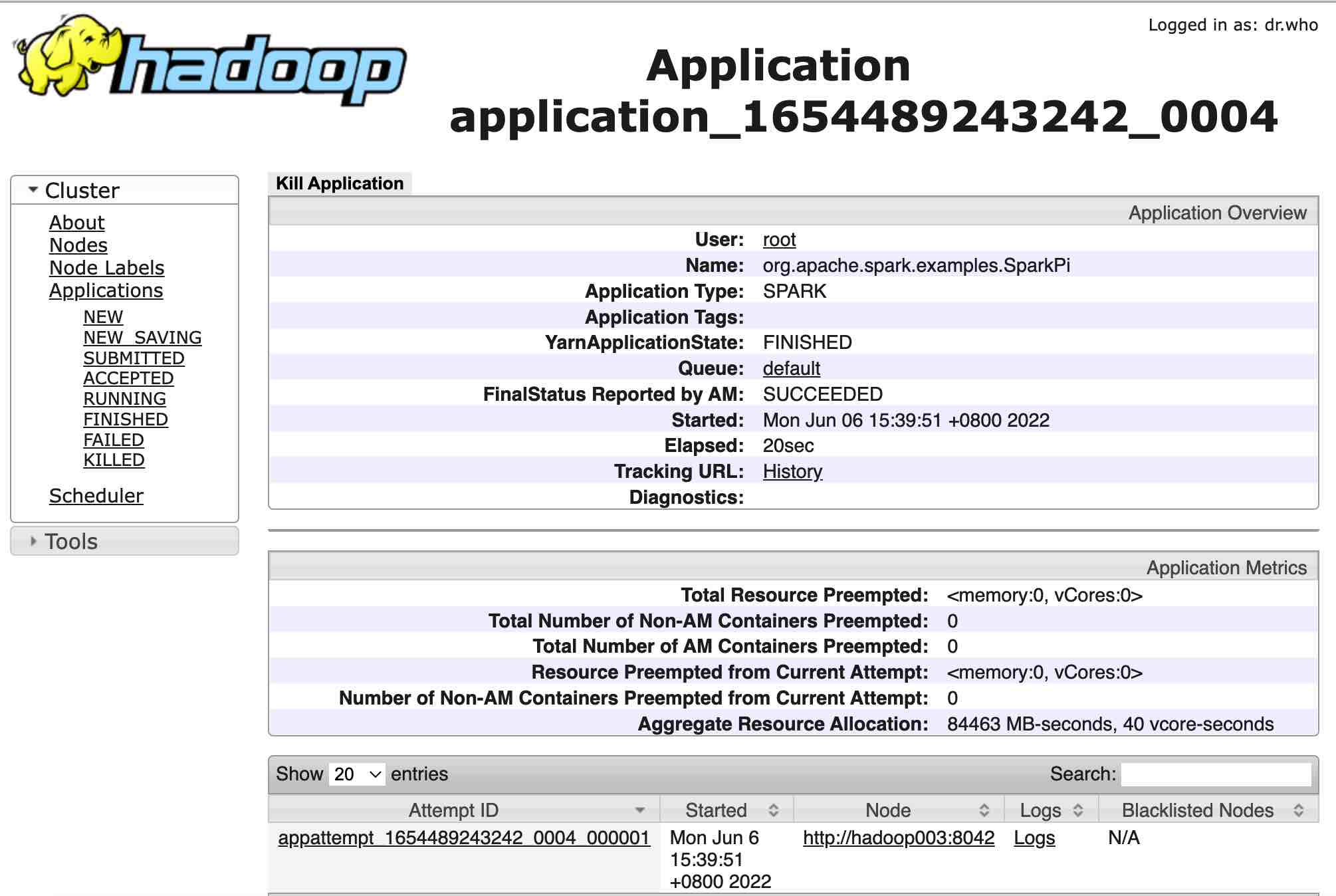 click to go the [Logs] link,
click to go the [Logs] link,

and then click the [stdout], we will find the result:
Pi is roughly 3.137823137823138
