1 Install
Download flink from apache, extract to /opt/module .
2 Configuration
2.1 Set environment variables
1
2
3
4
5
[root@hadoop001 ~]# cd /opt/module/flink-1.12.7/
[root@hadoop001 flink-1.12.7]# echo export FLINK_HOME=`pwd` >> /etc/profile
[root@hadoop001 flink-1.12.7]# echo export PATH=\$PATH:\$FLINK_HOME/bin >> /etc/profile
[root@hadoop001 flink-1.12.7]# echo export HADOOP_CONF_DIR=\$HADOOP_HOME/etc/hadoop >> /etc/profile
[root@hadoop001 flink-1.12.7]# source /etc/profile
2.2 config flink-conf.yaml
Edit conf/flink-conf.yaml, change the following options to:
1
2
3
4
5
6
7
8
jobmanager.rpc.address: hadoop001
taskmanager.numberOfTaskSlots: 2
web.submit.enable: true
jobmanager.archive.fs.dir: hdfs://ns/flink/completed-jobs/
historyserver.web.address: hadoop001
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://ns/flink/completed-jobs/
2.3 set masters
Update masters to hadoop001:8081
1
2
3
[root@hadoop001 conf]# echo hadoop001:8081 > masters
[root@hadoop001 conf]# cat masters
hadoop001:8081
2.4 set workers
Add hadoop001/2/3 to workers:
1
2
3
4
5
6
7
[root@hadoop001 conf]# echo "hadoop001
> hadoop002
> hadoop003" > workers
[root@hadoop001 conf]# cat workers
hadoop001
hadoop002
hadoop003
2.5 distribute to hadoop002/3
1
2
3
4
[root@hadoop001 module]# scp -r flink-1.12.7 hadoop002:`pwd`
[root@hadoop001 module]# scp -r flink-1.12.7 hadoop003:`pwd`
[root@hadoop001 module]# scp /etc/profile hadoop002:/etc
[root@hadoop001 module]# scp /etc/profile hadoop003:/etc
2.6 create job directory
1
2
[root@hadoop001 module]# hdfs dfs -mkdir -p hdfs://ns/flink/completed-jobs/
[root@hadoop001 module]# hdfs dfs -chmod 777 hdfs://ns/flink/completed-jobs/
3. Start cluster
3.1 Start cluster and history server
1
2
3
[root@hadoop001 module]# start-cluster.sh
[root@hadoop001 module]# historyserver.sh start
Starting historyserver daemon on host hadoop001.
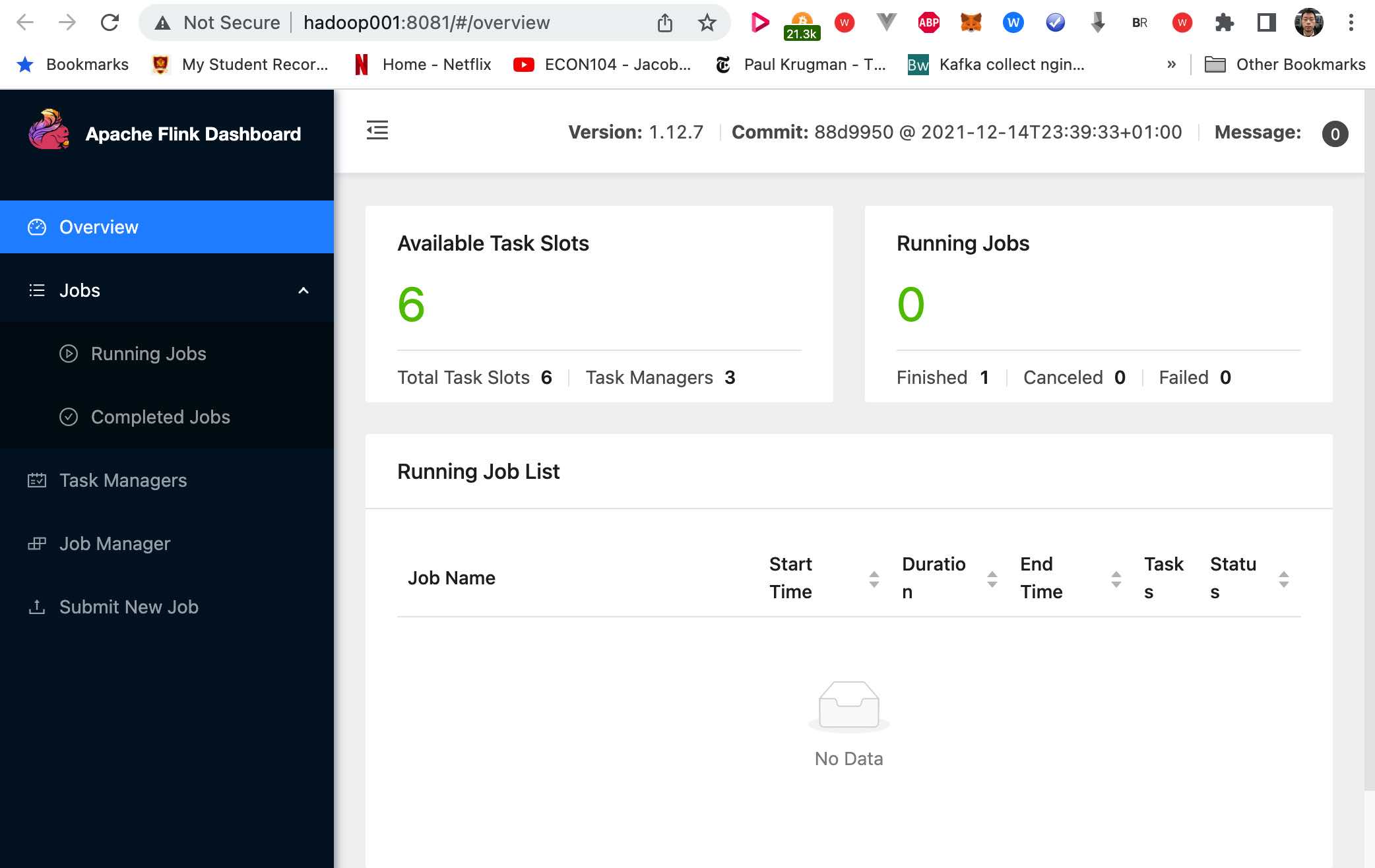
3.2 check in web ui
open http://hadoop001:8081/ in browser.
4 Run tasks
Launch a example word count task:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
[root@hadoop001 flink-1.12.7]# flink run ./examples/batch/WordCount.jar --input README.txt --output /root/readme-count.txt --parallelism 2
------------------------------------------------------------
The program finished with the following exception:
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: java.util.concurrent.ExecutionException: java.lang.RuntimeException: org.apache.flink.runtime.client.JobInitializationException: Could not instantiate JobManager.
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:366)
at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:219)
at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:114)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:812)
...
Caused by: java.io.FileNotFoundException: File README.txt does not exist or the user running Flink ('root') has insufficient permissions to access it.
at org.apache.flink.core.fs.local.LocalFileSystem.getFileStatus(LocalFileSystem.java:106)
at org.apache.flink.api.common.io.FileInputFormat.createInputSplits(FileInputFormat.java:598)
at org.apache.flink.api.common.io.FileInputFormat.createInputSplits(FileInputFormat.java:62)
at org.apache.flink.runtime.executiongraph.ExecutionJobVertex.<init>(ExecutionJobVertex.java:247)
... 18 more
File README.txt does not exist or the user running Flink (‘root’) has insufficient permissions to access it.
Should close HDFS in Standalone mode, and re-start cluster.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
[root@hadoop001 flink-1.12.7]# stop-dfs.sh
[root@hadoop001 flink-1.12.7]# stop-cluster.sh
Stopping taskexecutor daemon (pid: 51487) on host hadoop001.
Stopping taskexecutor daemon (pid: 51365) on host hadoop002.
Stopping taskexecutor daemon (pid: 49585) on host hadoop003.
[root@hadoop001 flink-1.12.7]# start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop001.
Starting taskexecutor daemon on host hadoop001.
Starting taskexecutor daemon on host hadoop002.
Starting taskexecutor daemon on host hadoop003.
[root@hadoop001 flink-1.12.7]# flink run ./examples/batch/WordCount.jar \
--input README.txt \
--output /root/readme-count.txt \
--parallelism 2
Job has been submitted with JobID 16f8f54c12b4c26ea8a95d719b63cdaa
Program execution finished
Job with JobID 16f8f54c12b4c26ea8a95d719b63cdaa has finished.
Job Runtime: 670 ms
Seems it works, but when I re-run flink while hdfs is on later, I still get job run completely.
So what’s the real reason of this ERROR?
According the webui, task was run on hadoop002, check it there. 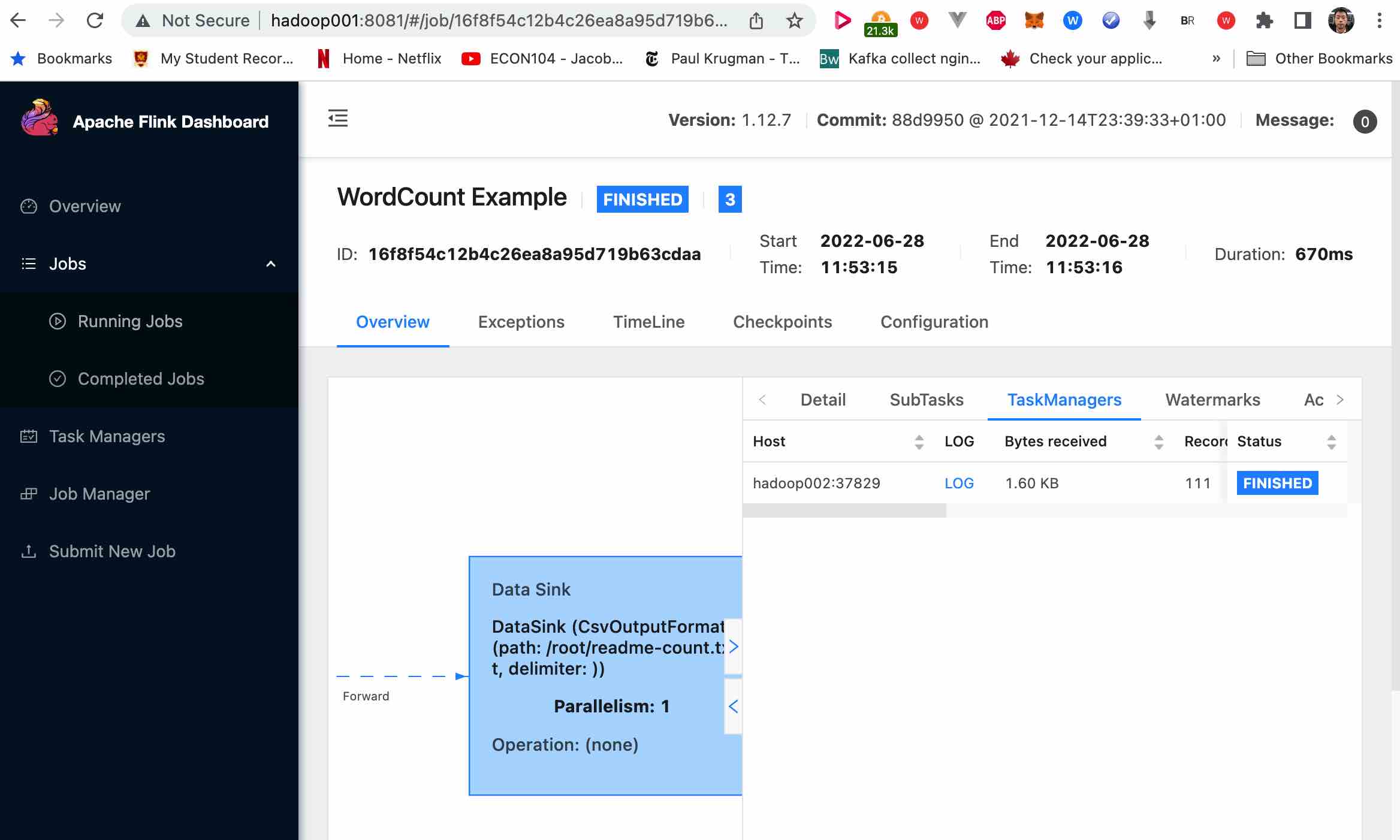
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
[root@hadoop002 ~]# ll
total 1574376
-rwxr-xr-x 1 root root 1612145664 Jun 27 21:38 bigdata.tar
drwxrwxrwx 8 501 games 4096 May 31 16:16 hadoop-install
-rw-r--r-- 1 root root 969 Jun 28 11:53 readme-count.txt
[root@hadoop002 ~]# more readme-count.txt
1 1
13 1
5d002 1
740 1
about 1
account 1
administration 1
algorithms 1
and 7
another 1
any 2
apache 5
as 1
ask 1
asymmetric 1
...
Flink successfully launched a task and output the result.
5 Fink on YARN
5.1 Session Mode
Features:
- Need to start a session and request resources before start jobs
- Do not need to request resources before start each job, this will boost efficiency
- Job Manager and Task Manager will keep running after jobs finished(wait for next job)
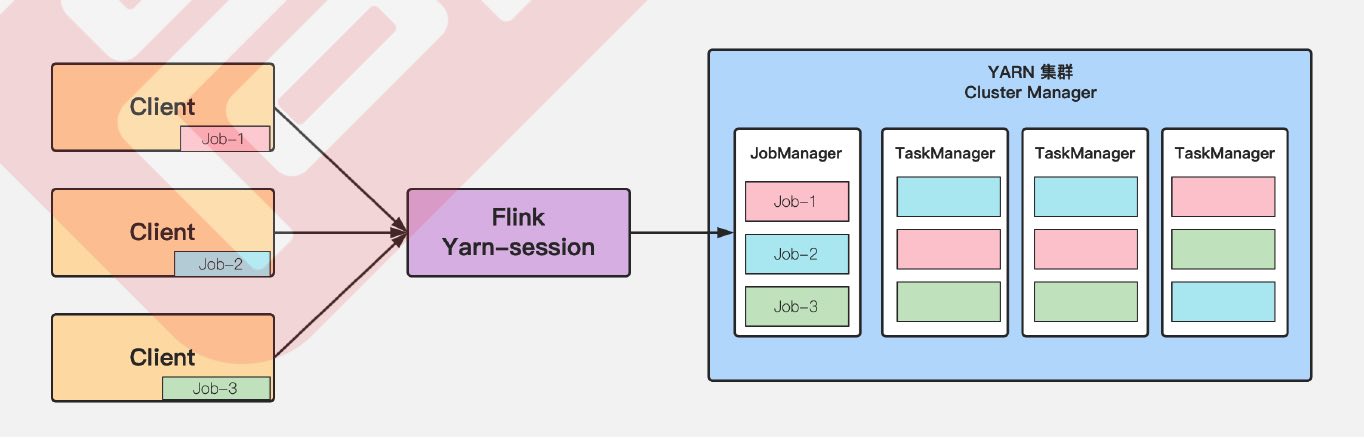
5.1.1 Start a session
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
[root@hadoop001 flink-1.12.7]# ./bin/yarn-session.sh -n 2 -tm 400 -s 1 -d
2022-06-28 17:01:56,478 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.address, hadoop001
2022-06-28 17:01:56,481 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.port, 6123
2022-06-28 17:01:56,482 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.memory.process.size, 1600m
2022-06-28 17:01:56,482 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.memory.process.size, 1728m
2022-06-28 17:01:56,482 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.numberOfTaskSlots, 2
2022-06-28 17:01:56,482 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: parallelism.default, 1
2022-06-28 17:01:56,482 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.execution.failover-strategy, region
2022-06-28 17:01:56,482 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: web.submit.enable, true
2022-06-28 17:01:56,483 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.archive.fs.dir, hdfs://ns/flink/completed-jobs/
2022-06-28 17:01:56,483 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: historyserver.web.address, hadoop001
2022-06-28 17:01:56,483 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: historyserver.web.port, 8082
2022-06-28 17:01:56,483 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: historyserver.archive.fs.dir, hdfs://ns/flink/completed-jobs/
2022-06-28 17:01:56,898 WARN org.apache.hadoop.util.NativeCodeLoader [] - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2022-06-28 17:01:57,003 INFO org.apache.flink.runtime.security.modules.HadoopModule [] - Hadoop user set to root (auth:SIMPLE)
2022-06-28 17:01:57,026 INFO org.apache.flink.runtime.security.modules.JaasModule [] - Jaas file will be created as /tmp/jaas-8628317349087201715.conf.
2022-06-28 17:01:57,045 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/opt/module/flink-1.12.7/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2022-06-28 17:01:57,308 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (160.000mb (167772162 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2022-06-28 17:01:57,318 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (172.800mb (181193935 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2022-06-28 17:01:57,459 INFO org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider [] - Failing over to rm2
2022-06-28 17:01:57,522 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured JobManager memory is 1600 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 448 MB may not be used by Flink.
2022-06-28 17:01:57,522 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured TaskManager memory is 1728 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 320 MB may not be used by Flink.
2022-06-28 17:01:57,522 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=1600, taskManagerMemoryMB=1728, slotsPerTaskManager=2}
2022-06-28 17:02:01,789 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (160.000mb (167772162 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2022-06-28 17:02:01,805 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1656406122617_0002
2022-06-28 17:02:02,044 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1656406122617_0002
2022-06-28 17:02:02,044 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2022-06-28 17:02:02,046 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2022-06-28 17:02:10,603 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2022-06-28 17:02:10,604 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hadoop002:41823 of application 'application_1656406122617_0002'.
JobManager Web Interface: http://hadoop002:41823
5.1.2 Start a job
Open another ternimal, launch a job:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
[root@hadoop001 flink-1.12.7]# ./bin/flink run ./examples/batch/WordCount.jar \
--input hdfs://hadoop001:9000/data/README.txt \
--output hdfs://hadoop001:9000/data/README-output
------------------------------------------------------------
The program finished with the following exception:
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: java.util.concurrent.ExecutionException: java.lang.RuntimeException: org.apache.flink.runtime.client.JobInitializationException: Could not instantiate JobManager.
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:366)
at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:219)
at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:114)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:812)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:246)
at org.apache.flink.client.cli.CliFrontend.parseAndRun(CliFrontend.java:1054)
at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:1132)
at org.apache.flink.runtime.security.contexts.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:28)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1132)
Caused by: java.lang.RuntimeException: java.util.concurrent.ExecutionException: java.lang.RuntimeException: org.apache.flink.runtime.client.JobInitializationException: Could not instantiate JobManager.
at org.apache.flink.util.ExceptionUtils.rethrow(ExceptionUtils.java:316)
at org.apache.flink.api.java.ExecutionEnvironment.executeAsync(ExecutionEnvironment.java:1061)
at org.apache.flink.client.program.ContextEnvironment.executeAsync(ContextEnvironment.java:129)
at org.apache.flink.client.program.ContextEnvironment.execute(ContextEnvironment.java:70)
at org.apache.flink.examples.java.wordcount.WordCount.main(WordCount.java:93)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:349)
... 8 more
Caused by: java.util.concurrent.ExecutionException: java.lang.RuntimeException: org.apache.flink.runtime.client.JobInitializationException: Could not instantiate JobManager.
at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1895)
at org.apache.flink.api.java.ExecutionEnvironment.executeAsync(ExecutionEnvironment.java:1056)
... 16 more
Caused by: java.lang.RuntimeException: org.apache.flink.runtime.client.JobInitializationException: Could not instantiate JobManager.
at org.apache.flink.util.ExceptionUtils.rethrow(ExceptionUtils.java:316)
at org.apache.flink.util.function.FunctionUtils.lambda$uncheckedFunction$2(FunctionUtils.java:75)
at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:602)
at java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:577)
at java.util.concurrent.CompletableFuture$Completion.run(CompletableFuture.java:442)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.flink.runtime.client.JobInitializationException: Could not instantiate JobManager.
at org.apache.flink.runtime.dispatcher.Dispatcher.lambda$createJobManagerRunner$5(Dispatcher.java:488)
at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1590)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
... 1 more
Caused by: org.apache.flink.runtime.client.JobExecutionException: Cannot initialize task 'DataSink (CsvOutputFormat (path: hdfs://hadoop001:9000/data/README-output, delimiter: ))': Could not find a file system implementation for scheme 'hdfs'. The scheme is not directly supported by Flink and no Hadoop file system to support this scheme could be loaded. For a full list of supported file systems, please see https://ci.apache.org/projects/flink/flink-docs-stable/ops/filesystems/.
at org.apache.flink.runtime.executiongraph.ExecutionGraphBuilder.buildGraph(ExecutionGraphBuilder.java:239)
at org.apache.flink.runtime.scheduler.SchedulerBase.createExecutionGraph(SchedulerBase.java:322)
at org.apache.flink.runtime.scheduler.SchedulerBase.createAndRestoreExecutionGraph(SchedulerBase.java:276)
at org.apache.flink.runtime.scheduler.SchedulerBase.<init>(SchedulerBase.java:249)
at org.apache.flink.runtime.scheduler.DefaultScheduler.<init>(DefaultScheduler.java:133)
at org.apache.flink.runtime.scheduler.DefaultSchedulerFactory.createInstance(DefaultSchedulerFactory.java:111)
at org.apache.flink.runtime.jobmaster.JobMaster.createScheduler(JobMaster.java:342)
at org.apache.flink.runtime.jobmaster.JobMaster.<init>(JobMaster.java:327)
at org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.createJobMasterService(DefaultJobMasterServiceFactory.java:95)
at org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.createJobMasterService(DefaultJobMasterServiceFactory.java:39)
at org.apache.flink.runtime.jobmaster.JobManagerRunnerImpl.<init>(JobManagerRunnerImpl.java:163)
at org.apache.flink.runtime.dispatcher.DefaultJobManagerRunnerFactory.createJobManagerRunner(DefaultJobManagerRunnerFactory.java:86)
at org.apache.flink.runtime.dispatcher.Dispatcher.lambda$createJobManagerRunner$5(Dispatcher.java:472)
... 4 more
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme 'hdfs'. The scheme is not directly supported by Flink and no Hadoop file system to support this scheme could be loaded. For a full list of supported file systems, please see https://ci.apache.org/projects/flink/flink-docs-stable/ops/filesystems/.
at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:531)
at org.apache.flink.core.fs.FileSystem.get(FileSystem.java:408)
at org.apache.flink.core.fs.Path.getFileSystem(Path.java:274)
at org.apache.flink.api.common.io.FileOutputFormat.initializeGlobal(FileOutputFormat.java:288)
at org.apache.flink.runtime.jobgraph.InputOutputFormatVertex.initializeOnMaster(InputOutputFormatVertex.java:110)
at org.apache.flink.runtime.executiongraph.ExecutionGraphBuilder.buildGraph(ExecutionGraphBuilder.java:235)
... 16 more
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Hadoop is not in the classpath/dependencies.
at org.apache.flink.core.fs.UnsupportedSchemeFactory.create(UnsupportedSchemeFactory.java:55)
at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:527)
... 21 more
Could not find a file system implementation for scheme ‘hdfs’. The scheme is not directly supported by Flink and no Hadoop file system to support this scheme could be loaded. This is because flink did not provider hdfs connector in its self by default, specify HADOOP_CLASSPATH to solve this:
1
2
3
[root@hadoop001 ~]# hadoop classpath
/opt/module/hadoop-2.7.3/etc/hadoop:/opt/module/hadoop-2.7.3/share/hadoop/common/lib/*:/opt/module/hadoop-2.7.3/share/hadoop/common/*:/opt/module/hadoop-2.7.3/share/hadoop/hdfs:/opt/module/hadoop-2.7.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-2.7.3/share/hadoop/hdfs/*:/opt/module/hadoop-2.7.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-2.7.3/share/hadoop/yarn/*:/opt/module/hadoop-2.7.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-2.7.3/share/hadoop/mapreduce/*:/opt/module/hadoop-2.7.3/contrib/capacity-scheduler/*.jar
[root@hadoop001 ~]# export HADOOP_CLASSPATH=`hadoop classpath`
Restart again:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
[root@hadoop001 flink-1.12.7]# ./bin/flink run ./examples/batch/WordCount.jar \
--input hdfs://hadoop001:9000/data/README.txt \
--output hdfs://hadoop001:9000/data/README-output
2022-06-28 17:03:58,583 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
2022-06-28 17:03:58,583 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
2022-06-28 17:03:59,890 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/opt/module/flink-1.12.7/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2022-06-28 17:04:00,110 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2022-06-28 17:04:00,123 INFO org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider [] - Failing over to rm2
2022-06-28 17:04:00,145 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hadoop002:41823 of application 'application_1656406122617_0002'.
Job has been submitted with JobID d2eb86daf53fc0eea7f5a8ec766a2b8a
Program execution finished
Job with JobID d2eb86daf53fc0eea7f5a8ec766a2b8a has finished.
Job Runtime: 13150 ms
Check the output in hdfs:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
[root@hadoop001 flink-1.12.7]# hdfs dfs -ls /data
Found 7 items
-rw-r--r-- 3 root supergroup 969 2022-06-28 17:04 /data/README-output
-rw-r--r-- 3 root supergroup 1309 2022-06-28 16:25 /data/README.txt
...
[root@hadoop001 flink-1.12.7]# hdfs dfs -cat /data/README-output
1 1
13 1
5d002 1
740 1
about 1
account 1
administration 1
algorithms 1
and 7
another 1
any 2
apache 5
as 1
ask 1
asymmetric 1
at 1
before 1
bis 2
both 1
bureau 1
c 1
check 1
classified 1
code 2
com 1
commerce 1
commodity 1
concerning 1
control 1
country 3
cryptographic 2
currently 1
department 1
dev 1
distribution 2
eccn 1
eligible 1
enc 1
encryption 3
exception 2
export 5
flink 5
for 4
form 1
foundation 1
functions 1
github 2
government 1
has 1
have 2
http 1
https 2
if 2
import 2
in 1
includes 2
industry 1
information 3
is 1
it 1
latest 1
laws 1
license 1
lists 1
mailing 1
makes 1
manner 1
may 1
more 1
number 1
object 1
of 5
on 2
or 3
org 4
our 3
performing 1
permitted 1
please 2
policies 1
possession 2
questions 1
re 2
regulations 2
reside 1
restrictions 1
s 2
section 1
security 2
see 3
software 8
source 1
technology 1
the 8
this 4
to 2
tsu 1
u 1
under 1
unrestricted 1
use 2
user 1
using 2
visit 1
wassenaar 1
website 1
which 2
with 1
www 1
you 2
your 1
5.2 Pre-Job Model
Features:
- Assign resources for each job
- Every job has its own JobManager and TaskManager
- Resource will be released as soon as the job finished
- Re-requesting resources each time a job is started which can effect execution efficiency
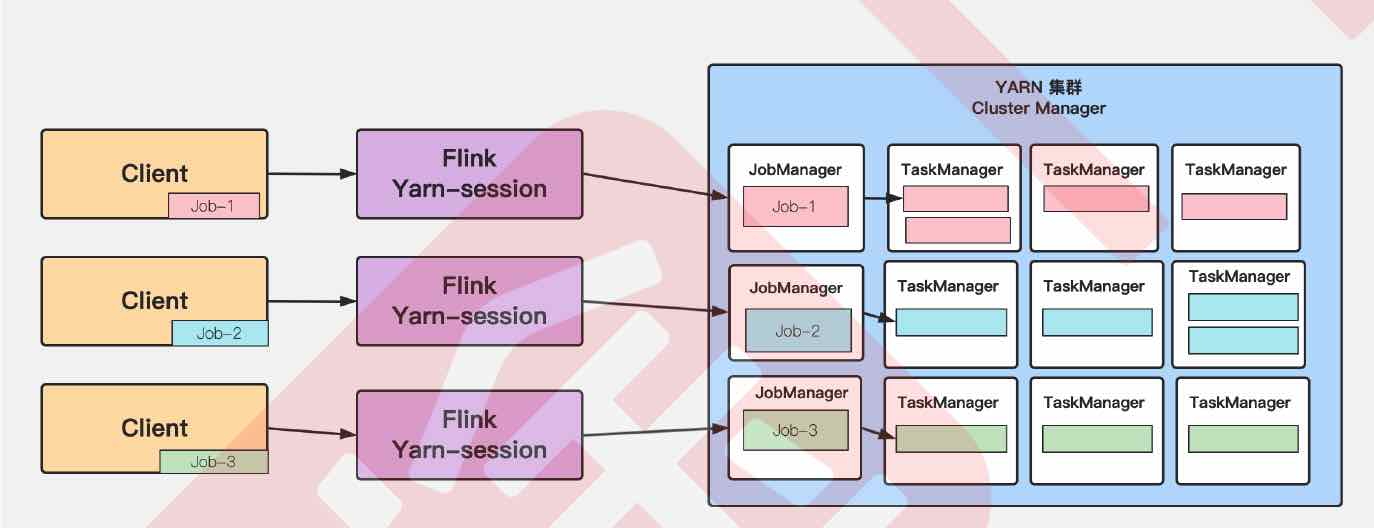
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
[root@hadoop001 flink-1.12.7]# flink run -m yarn-cluster ./examples/batch/WordCount.jar \
> --input hdfs://hadoop001:9000/data/README.txt
--Printing result to stdout. Use --output to specify output path.
2022-06-28 17:24:43,053 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/opt/module/flink-1.12.7/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2022-06-28 17:24:43,284 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2022-06-28 17:24:43,350 INFO org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider [] - Failing over to rm2
2022-06-28 17:24:43,392 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured JobManager memory is 1600 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 448 MB may not be used by Flink.
2022-06-28 17:24:43,392 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured TaskManager memory is 1728 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 320 MB may not be used by Flink.
2022-06-28 17:24:43,392 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=1600, taskManagerMemoryMB=1728, slotsPerTaskManager=2}
2022-06-28 17:24:46,948 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1656406122617_0004
2022-06-28 17:24:47,024 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1656406122617_0004
2022-06-28 17:24:47,024 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2022-06-28 17:24:47,029 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2022-06-28 17:24:53,065 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2022-06-28 17:24:53,066 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hadoop002:43651 of application 'application_1656406122617_0004'.
Job has been submitted with JobID 2011f234276f307514140b87d19bc718
Program execution finished
Job with JobID 2011f234276f307514140b87d19bc718 has finished.
Job Runtime: 13068 ms
Accumulator Results:
- a6f4a424c916fede0c95f84dc38d1aba (java.util.ArrayList) [111 elements]
(1,1)
(13,1)
(5d002,1)
(740,1)
(about,1)
(account,1)
(administration,1)
(algorithms,1)
(and,7)
(another,1)
(any,2)
(apache,5)
(as,1)
(ask,1)
(asymmetric,1)
(at,1)
(before,1)
(bis,2)
(both,1)
(bureau,1)
(c,1)
(check,1)
(classified,1)
(code,2)
(com,1)
(commerce,1)
(commodity,1)
(concerning,1)
(control,1)
(country,3)
(cryptographic,2)
(currently,1)
(department,1)
(dev,1)
(distribution,2)
(eccn,1)
(eligible,1)
(enc,1)
(encryption,3)
(exception,2)
(export,5)
(flink,5)
(for,4)
(form,1)
(foundation,1)
(functions,1)
(github,2)
(government,1)
(has,1)
(have,2)
(http,1)
(https,2)
(if,2)
(import,2)
(in,1)
(includes,2)
(industry,1)
(information,3)
(is,1)
(it,1)
(latest,1)
(laws,1)
(license,1)
(lists,1)
(mailing,1)
(makes,1)
(manner,1)
(may,1)
(more,1)
(number,1)
(object,1)
(of,5)
(on,2)
(or,3)
(org,4)
(our,3)
(performing,1)
(permitted,1)
(please,2)
(policies,1)
(possession,2)
(questions,1)
(re,2)
(regulations,2)
(reside,1)
(restrictions,1)
(s,2)
(section,1)
(security,2)
(see,3)
(software,8)
(source,1)
(technology,1)
(the,8)
(this,4)
(to,2)
(tsu,1)
(u,1)
(under,1)
(unrestricted,1)
(use,2)
(user,1)
(using,2)
(visit,1)
(wassenaar,1)
(website,1)
(which,2)
(with,1)
(www,1)
(you,2)
(your,1)