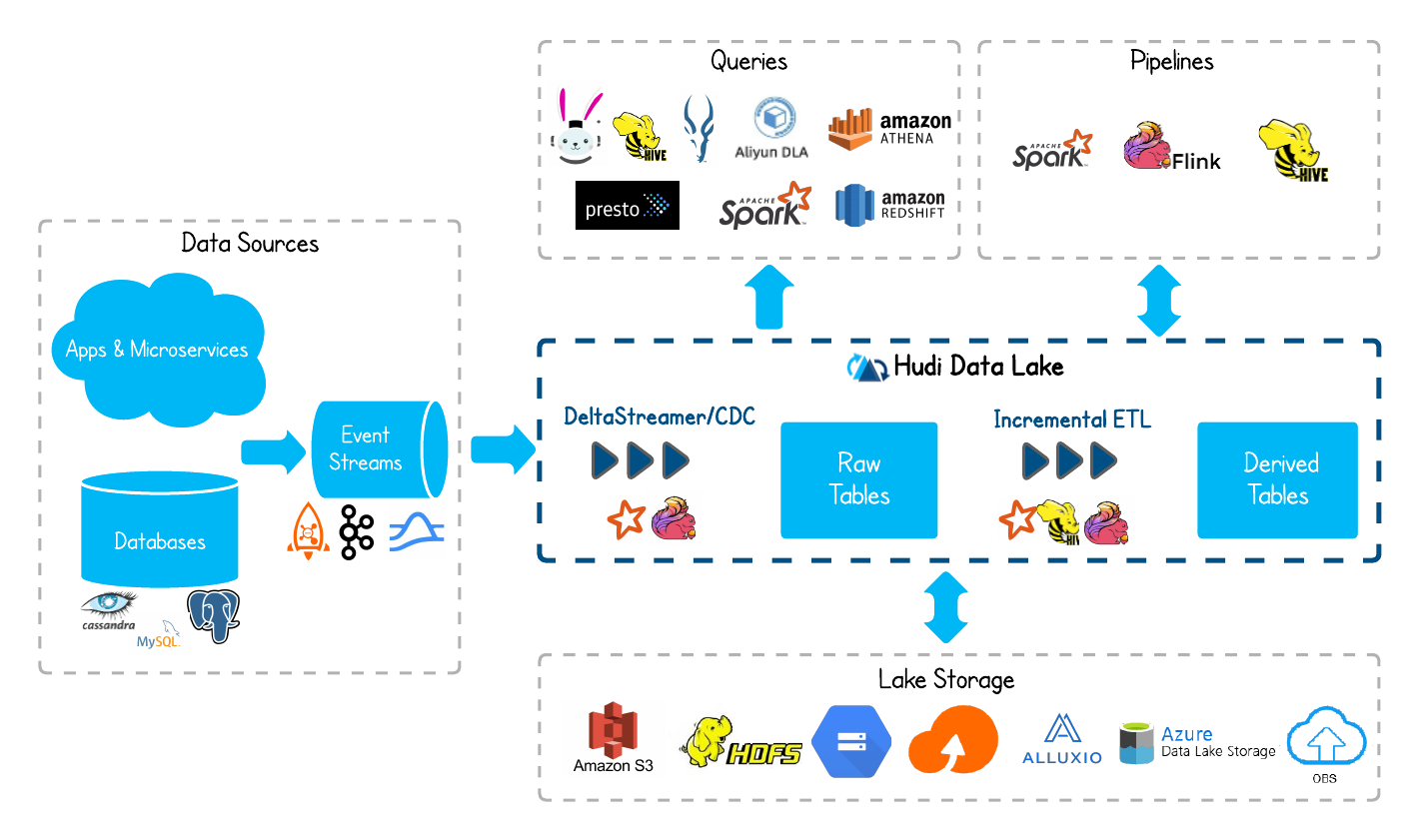
Overview
Hudi is a rich platform to build streaming data lakes with incremental data pipelines on a self-managing database layer, while being optimized for lake engines and regular batch processing.
Features
- Upserts, Deletes with fast, pluggable indexing.
- Incremental queries, Record level change streams.
- Transactions, Rollbacks, Concurrency Control.
- SQL Read/Writes from Spark, Presto, Trino, Hive & more.
- Automatic file sizing, data clustering, compactions, cleaning.
- Streaming ingestion, Built-in CDC sources & tools.
- Built-in metadata tracking for scalable storage access.
- Backwards compatible schema evolution and enforcement.
Concept
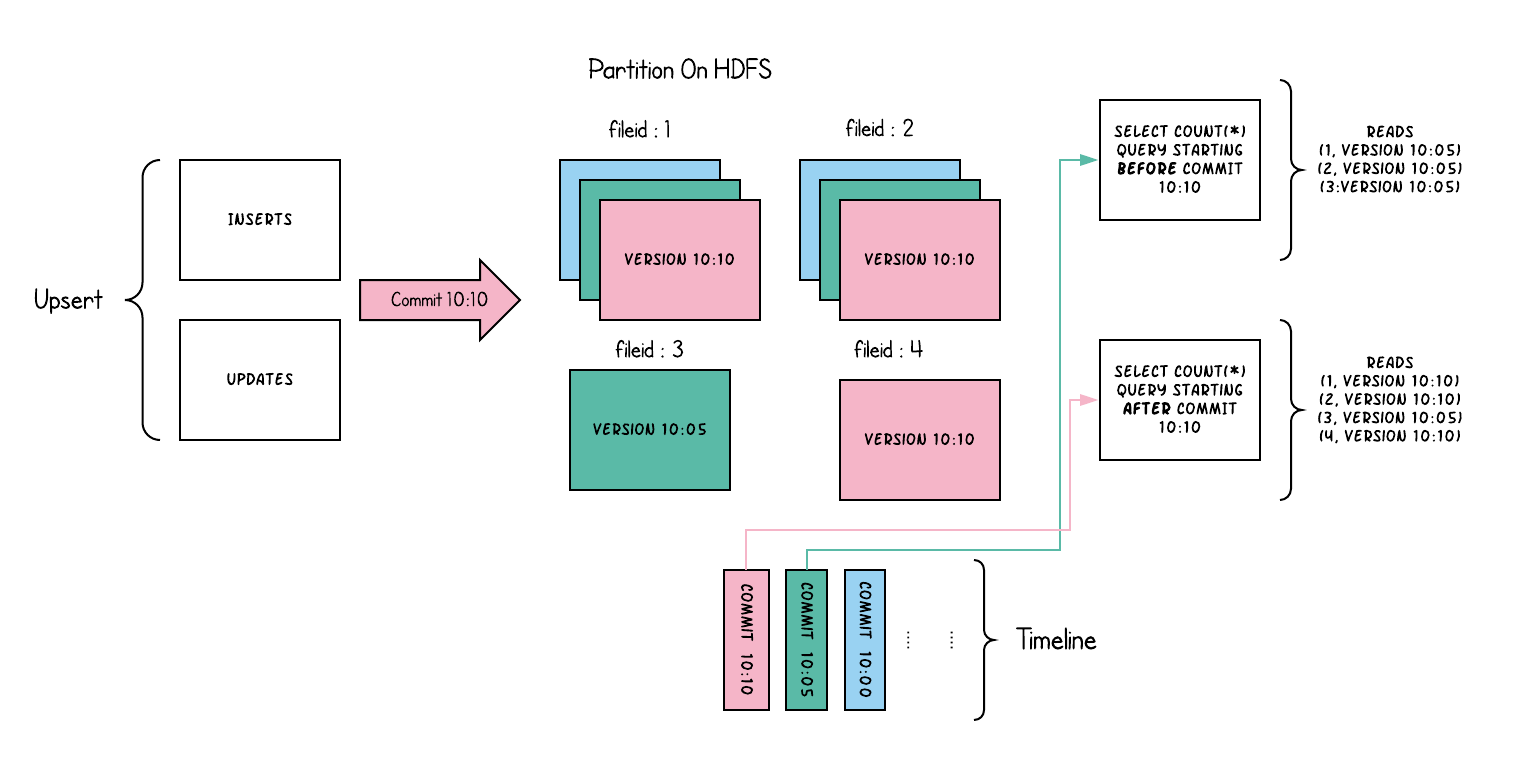
Copy On Write Table
Copy-On-Write table only contain the base/columnar file and each commit(insert, update or delete) will produce a new version of the file.
So, the write amplification is much higher, while the read amplification is zero. This is suitable for analytical workloads, which is read-heavy in most of time.
Merge On Read Table
Merge on read table is a superset of copy-on-write, it still supports read optimized queries of the table. Additionally, it stores incoming upserts for each file group, onto a row based delta log.
It applying the delta log onto the latest version of each file for queries.
This table attempts to balance read and write amplification intelligently.
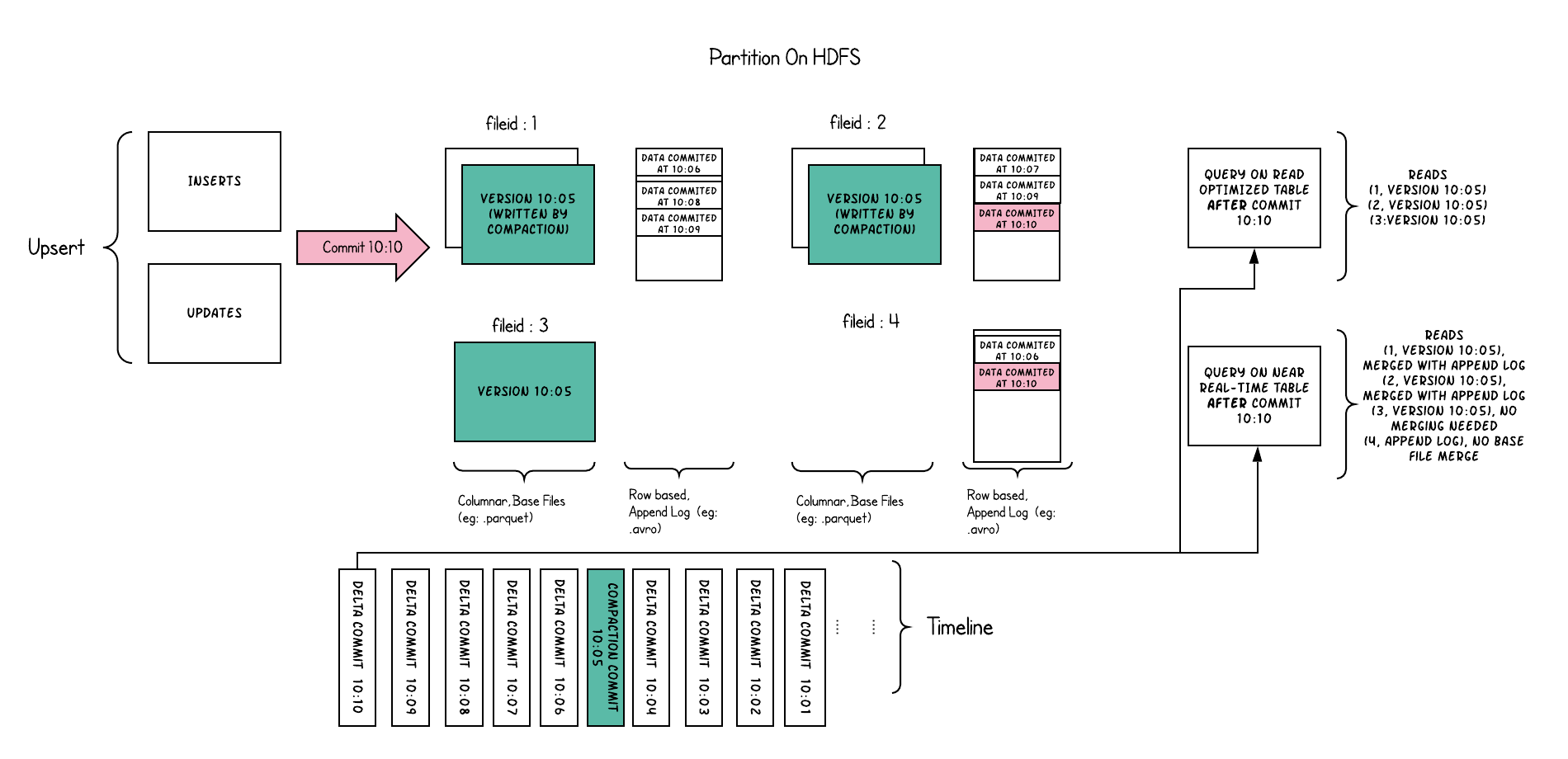
- A periodic compaction process will merge the changes from the delta log and produces a new version of base file, as a snapshot.
- There are two ways of query,
- Read Optimized query only see data on base files, like copy-on-write before.
- Snapshot Query will merge the delta log on base file, and always see the freshest data.
Spark Guide
Let demonstrate Hudi’s capabilities using spark-shell.
Install Spark3.x/2.x first, launch spark-shell with the following parameters. Note: my spark is 3.2, if you are using a different version, reference the Hudi quick start guide.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
[root@hadoop001 ~]# spark-shell \
> --packages org.apache.hudi:hudi-spark3.2-bundle_2.12:0.11.1 \
> --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
> --conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
> --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
Ivy Default Cache set to: /root/.ivy2/cache
The jars for the packages stored in: /root/.ivy2/jars
org.apache.hudi#hudi-spark3.2-bundle_2.12 added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-a3b1b183-3684-4c7e-a827-e76a0aaf46ec;1.0
confs: [default]
found org.apache.hudi#hudi-spark3.2-bundle_2.12;0.11.1 in central
:: resolution report :: resolve 264ms :: artifacts dl 3ms
:: modules in use:
org.apache.hudi#hudi-spark3.2-bundle_2.12;0.11.1 from central in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 1 | 0 | 0 | 0 || 1 | 0 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent-a3b1b183-3684-4c7e-a827-e76a0aaf46ec
confs: [default]
0 artifacts copied, 1 already retrieved (0kB/4ms)
22/07/24 17:03:07 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://hadoop001:4040
Spark context available as 'sc' (master = local[*], app id = local-1658653396150).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.2.1
/_/
Using Scala version 2.12.15 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_231)
Type in expressions to have them evaluated.
Type :help for more information.
1. Import libraries and define table name and store path
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
scala> import org.apache.hudi.QuickstartUtils._
import org.apache.hudi.QuickstartUtils._
scala> import scala.collection.JavaConversions._
import scala.collection.JavaConversions._
scala> import org.apache.spark.sql.SaveMode._
import org.apache.spark.sql.SaveMode._
scala> import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceReadOptions._
scala> import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.DataSourceWriteOptions._
scala> import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.config.HoodieWriteConfig._
scala> val table = "trips_cow"
table: String = trips_cow
scala> val path = "file:///tmp/trips_cow"
path: String = file:///tmp/trips_cow
scala> val gen = new DataGenerator
gen: org.apache.hudi.QuickstartUtils.DataGenerator = org.apache.hudi.QuickstartUtils$DataGenerator@2c5241ca
2. Generate sample data and insert to table:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
scala> val inserts = convertToStringList(gen.generateInserts(10))
inserts: java.util.List[String] = [{"ts": 1658541514983, "uuid": "647f9271-fad6-442c-af45-4838fb57a94f", "rider": "rider-213", "driver": "driver-213", "begin_lat": 0.4726905879569653, "begin_lon": 0.46157858450465483, "end_lat": 0.754803407008858, "end_lon": 0.9671159942018241, "fare": 34.158284716382845, "partitionpath": "americas/brazil/sao_paulo"}, {"ts": 1658299763668, "uuid": "f527d36d-a8b1-4d09-a204-d7c6120a824e", "rider": "rider-213", "driver": "driver-213", "begin_lat": 0.6100070562136587, "begin_lon": 0.8779402295427752, "end_lat": 0.3407870505929602, "end_lon": 0.5030798142293655, "fare": 43.4923811219014, "partitionpath": "americas/brazil/sao_paulo"}, {"ts": 1658206246459, "uuid": "96237640-eba7-4c6a-a9eb-a1dc3adf93c2", "rider": "rider-213", "driver"...
scala> val df = spark.read.json(spark.sparkContext.parallelize(inserts,2))
warning: one deprecation (since 2.12.0)
warning: one deprecation (since 2.2.0)
warning: two deprecations in total; for details, enable `:setting -deprecation' or `:replay -deprecation'
df: org.apache.spark.sql.DataFrame = [begin_lat: double, begin_lon: double ... 8 more fields]
scala> df.write.format("hudi").
| options(getQuickstartWriteConfigs).
| option(PRECOMBINE_FIELD_OPT_KEY, "ts").
| option(RECORDKEY_FIELD_OPT_KEY, "uuid").
| option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
| option(TABLE_NAME, table).
| mode(Overwrite).
| save(path)
warning: one deprecation; for details, enable `:setting -deprecation' or `:replay -deprecation'
22/07/24 17:07:09 WARN config.DFSPropertiesConfiguration: Cannot find HUDI_CONF_DIR, please set it as the dir of hudi-defaults.conf
22/07/24 17:07:10 WARN config.DFSPropertiesConfiguration: Properties file file:/etc/hudi/conf/hudi-defaults.conf not found. Ignoring to load props file
22/07/24 17:07:11 WARN metadata.HoodieBackedTableMetadata: Metadata table was not found at path file:///tmp/trips_cow/.hoodie/metadata
3. Query data
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
scala> val snapshotDF = spark.read.format("hudi").load(path)
snapshotDF: org.apache.spark.sql.DataFrame = [_hoodie_commit_time: string, _hoodie_commit_seqno: string ... 13 more fields]
scala> snapshotDF.createOrReplaceTempView("trips_snapshot")
scala> spark.sql("select fare,begin_lon, begin_lat, ts from trips_snapshot").show
+------------------+-------------------+-------------------+-------------+
| fare| begin_lon| begin_lat| ts|
+------------------+-------------------+-------------------+-------------+
| 33.92216483948643| 0.9694586417848392| 0.1856488085068272|1658487680566|
| 64.27696295884016| 0.4923479652912024| 0.5731835407930634|1658206246459|
| 27.79478688582596| 0.6273212202489661|0.11488393157088261|1658499822135|
| 93.56018115236618|0.14285051259466197|0.21624150367601136|1658393393674|
|19.179139106643607| 0.7528268153249502| 0.8742041526408587|1658248455875|
|34.158284716382845|0.46157858450465483| 0.4726905879569653|1658541514983|
| 66.62084366450246|0.03844104444445928| 0.0750588760043035|1658074165484|
| 43.4923811219014| 0.8779402295427752| 0.6100070562136587|1658299763668|
| 41.06290929046368| 0.8192868687714224| 0.651058505660742|1658463149458|
|17.851135255091155| 0.5644092139040959| 0.40613510977307|1658109228990|
+------------------+-------------------+-------------------+-------------+
scala> spark.sql("select _hoodie_commit_time, _hoodie_record_key, rider,driver,fare from trips_snapshot").show
+-------------------+--------------------+---------+----------+------------------+
|_hoodie_commit_time| _hoodie_record_key| rider| driver| fare|
+-------------------+--------------------+---------+----------+------------------+
| 20220724170710034|bd1e5da7-d0dc-453...|rider-213|driver-213| 33.92216483948643|
| 20220724170710034|96237640-eba7-4c6...|rider-213|driver-213| 64.27696295884016|
| 20220724170710034|7c786032-0cbd-41b...|rider-213|driver-213| 27.79478688582596|
| 20220724170710034|08085729-be36-48c...|rider-213|driver-213| 93.56018115236618|
| 20220724170710034|56897807-6879-4d6...|rider-213|driver-213|19.179139106643607|
| 20220724170710034|647f9271-fad6-442...|rider-213|driver-213|34.158284716382845|
| 20220724170710034|a1ad2dc0-ced2-478...|rider-213|driver-213| 66.62084366450246|
| 20220724170710034|f527d36d-a8b1-4d0...|rider-213|driver-213| 43.4923811219014|
| 20220724170710034|7330694e-0949-44f...|rider-213|driver-213| 41.06290929046368|
| 20220724170710034|4d12bbfe-ecf0-470...|rider-213|driver-213|17.851135255091155|
+-------------------+--------------------+---------+----------+------------------+
4. Time travel query
Hudi support 3 types of date format, “20220724170710034”, “2022-07-24 14:11:08.200”, and “2022-07-24”.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
scala> spark.read.format("hudi").option("as.of.instant", "20220724170710034").load(path).show
+-------------------+--------------------+--------------------+----------------------+--------------------+-------------------+-------------------+----------+-------------------+-------------------+------------------+---------+-------------+--------------------+--------------------+
|_hoodie_commit_time|_hoodie_commit_seqno| _hoodie_record_key|_hoodie_partition_path| _hoodie_file_name| begin_lat| begin_lon| driver| end_lat| end_lon| fare| rider| ts| uuid| partitionpath|
+-------------------+--------------------+--------------------+----------------------+--------------------+-------------------+-------------------+----------+-------------------+-------------------+------------------+---------+-------------+--------------------+--------------------+
| 20220724170710034|20220724170710034...|bd1e5da7-d0dc-453...| americas/united_s...|45b68116-ab83-4be...| 0.1856488085068272| 0.9694586417848392|driver-213|0.38186367037201974|0.25252652214479043| 33.92216483948643|rider-213|1658487680566|bd1e5da7-d0dc-453...|americas/united_s...|
| 20220724170710034|20220724170710034...|96237640-eba7-4c6...| americas/united_s...|45b68116-ab83-4be...| 0.5731835407930634| 0.4923479652912024|driver-213|0.08988581780930216|0.42520899698713666| 64.27696295884016|rider-213|1658206246459|96237640-eba7-4c6...|americas/united_s...|
| 20220724170710034|20220724170710034...|7c786032-0cbd-41b...| americas/united_s...|45b68116-ab83-4be...|0.11488393157088261| 0.6273212202489661|driver-213| 0.7454678537511295| 0.3954939864908973| 27.79478688582596|rider-213|1658499822135|7c786032-0cbd-41b...|americas/united_s...|
| 20220724170710034|20220724170710034...|08085729-be36-48c...| americas/united_s...|45b68116-ab83-4be...|0.21624150367601136|0.14285051259466197|driver-213| 0.5890949624813784| 0.0966823831927115| 93.56018115236618|rider-213|1658393393674|08085729-be36-48c...|americas/united_s...|
| 20220724170710034|20220724170710034...|56897807-6879-4d6...| americas/united_s...|45b68116-ab83-4be...| 0.8742041526408587| 0.7528268153249502|driver-213| 0.9197827128888302| 0.362464770874404|19.179139106643607|rider-213|1658248455875|56897807-6879-4d6...|americas/united_s...|
| 20220724170710034|20220724170710034...|647f9271-fad6-442...| americas/brazil/s...|8c00f865-5dad-47e...| 0.4726905879569653|0.46157858450465483|driver-213| 0.754803407008858| 0.9671159942018241|34.158284716382845|rider-213|1658541514983|647f9271-fad6-442...|americas/brazil/s...|
| 20220724170710034|20220724170710034...|a1ad2dc0-ced2-478...| americas/brazil/s...|8c00f865-5dad-47e...| 0.0750588760043035|0.03844104444445928|driver-213|0.04376353354538354| 0.6346040067610669| 66.62084366450246|rider-213|1658074165484|a1ad2dc0-ced2-478...|americas/brazil/s...|
| 20220724170710034|20220724170710034...|f527d36d-a8b1-4d0...| americas/brazil/s...|8c00f865-5dad-47e...| 0.6100070562136587| 0.8779402295427752|driver-213| 0.3407870505929602| 0.5030798142293655| 43.4923811219014|rider-213|1658299763668|f527d36d-a8b1-4d0...|americas/brazil/s...|
| 20220724170710034|20220724170710034...|7330694e-0949-44f...| asia/india/chennai|57fe6b92-28f9-4fe...| 0.651058505660742| 0.8192868687714224|driver-213|0.20714896002914462|0.06224031095826987| 41.06290929046368|rider-213|1658463149458|7330694e-0949-44f...| asia/india/chennai|
| 20220724170710034|20220724170710034...|4d12bbfe-ecf0-470...| asia/india/chennai|57fe6b92-28f9-4fe...| 0.40613510977307| 0.5644092139040959|driver-213| 0.798706304941517|0.02698359227182834|17.851135255091155|rider-213|1658109228990|4d12bbfe-ecf0-470...| asia/india/chennai|
+-------------------+--------------------+--------------------+----------------------+--------------------+-------------------+-------------------+----------+-------------------+-------------------+------------------+---------+-------------+--------------------+--------------------+
5. Update data
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
scala> val updates = convertToStringList(gen.generateUpdates(10))
updates: java.util.List[String] = [{"ts": 1658258854704, "uuid": "96237640-eba7-4c6a-a9eb-a1dc3adf93c2", "rider": "rider-243", "driver": "driver-243", "begin_lat": 0.9045189017781902, "begin_lon": 0.38697902072535484, "end_lat": 0.21932410786717094, "end_lon": 0.7816060218244935, "fare": 44.596839246210095, "partitionpath": "americas/united_states/san_francisco"}, {"ts": 1658634541542, "uuid": "a1ad2dc0-ced2-478f-8f84-58adb6134427", "rider": "rider-243", "driver": "driver-243", "begin_lat": 0.856152038750905, "begin_lon": 0.3132477949501916, "end_lat": 0.8742438057467156, "end_lon": 0.26923247017036556, "fare": 2.4995362119815567, "partitionpath": "americas/brazil/sao_paulo"}, {"ts": 1658586965276, "uuid": "96237640-eba7-4c6a-a9eb-a1dc3adf93c2", "rider": "rider...
scala> val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
warning: one deprecation (since 2.12.0)
warning: one deprecation (since 2.2.0)
warning: two deprecations in total; for details, enable `:setting -deprecation' or `:replay -deprecation'
df: org.apache.spark.sql.DataFrame = [begin_lat: double, begin_lon: double ... 8 more fields]
scala> df.write.format("hudi").
| options(getQuickstartWriteConfigs).
| option(PRECOMBINE_FIELD_OPT_KEY, "ts").
| option(RECORDKEY_FIELD_OPT_KEY, "uuid").
| option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
| option(TABLE_NAME,table).
| mode(Append).
| save(path)
warning: one deprecation; for details, enable `:setting -deprecation' or `:replay -deprecation'
6. Incremental query
Get insert time in step 2:
1
2
3
4
5
scala> val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from trips_snapshot order by commitTime").map(k => k.getString(0)).take(50)
scala> val beginTime = commits(0)
beginTime: String = 20220724170710034
Load data after begine time and then do the query:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
scala> val incDF = spark.read.format("hudi").
| option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
| option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
| load(path)
incDF: org.apache.spark.sql.DataFrame = [_hoodie_commit_time: string, _hoodie_commit_seqno: string ... 13 more fields]
scala> incDF.createOrReplaceTempView("trips_inc")
scala> spark.sql("select _hoodie_commit_time, begin_lon, begin_lat, driver, fare from trips_inc").show
+-------------------+-------------------+-------------------+----------+------------------+
|_hoodie_commit_time| begin_lon| begin_lat| driver| fare|
+-------------------+-------------------+-------------------+----------+------------------+
| 20220724173538717| 0.1072756362186601| 0.244841817279154|driver-243|15.119997249522644|
| 20220724173538717| 0.7071871604905721| 0.876334576190389|driver-243| 51.42305232303094|
| 20220724173538717|0.06105928762642976| 0.508361582050114|driver-243|59.071923248697225|
| 20220724173538717| 0.3132477949501916| 0.856152038750905|driver-243|2.4995362119815567|
| 20220724173538717|0.22991770617403628| 0.6923616674358241|driver-243| 89.45841313717807|
| 20220724173538717| 0.8150991077375751|0.01925237918893319|driver-243| 71.08018349571618|
+-------------------+-------------------+-------------------+----------+------------------+
7. Point in time query
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
scala> val beginTime = "000"
beginTime: String = 000
scala> val endTime = "20220724170710034"
endTime: String = 20220724170710034
scala> val pointDF = spark.read.format("hudi").
| option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
| option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
| option(END_INSTANTTIME_OPT_KEY, endTime).
| load(path)
pointDF: org.apache.spark.sql.DataFrame = [_hoodie_commit_time: string, _hoodie_commit_seqno: string ... 13 more fields]
scala> pointDF.createOrReplaceTempView("trips_point")
scala> spark.sql("select _hoodie_commit_time, driver, begin_lon, fare from trips_point").show
+-------------------+----------+-------------------+------------------+
|_hoodie_commit_time| driver| begin_lon| fare|
+-------------------+----------+-------------------+------------------+
| 20220724170710034|driver-213| 0.9694586417848392| 33.92216483948643|
| 20220724170710034|driver-213| 0.4923479652912024| 64.27696295884016|
| 20220724170710034|driver-213| 0.6273212202489661| 27.79478688582596|
| 20220724170710034|driver-213|0.14285051259466197| 93.56018115236618|
| 20220724170710034|driver-213| 0.7528268153249502|19.179139106643607|
| 20220724170710034|driver-213|0.46157858450465483|34.158284716382845|
| 20220724170710034|driver-213|0.03844104444445928| 66.62084366450246|
| 20220724170710034|driver-213| 0.8779402295427752| 43.4923811219014|
| 20220724170710034|driver-213| 0.8192868687714224| 41.06290929046368|
| 20220724170710034|driver-213| 0.5644092139040959|17.851135255091155|
+-------------------+----------+-------------------+------------------+
8. Delete data
There are 10 records in the table, we are going to delete 3 of them:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
scala> spark.sql("select uuid, partitionpath from trips_snapshot").count
res4: Long = 10
scala> val df = spark.sql("select uuid,partitionpath from trips_snapshot").limit(3)
df: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [uuid: string, partitionpath: string]
scala> val deletes = gen.generateDeletes(df.collectAsList)
deletes: java.util.List[String] = [{"ts": "0.0","uuid": "bd1e5da7-d0dc-4532-8aba-8a09d230eeea","partitionpath": "americas/united_states/san_francisco"}, {"ts": "0.0","uuid": "96237640-eba7-4c6a-a9eb-a1dc3adf93c2","partitionpath": "americas/united_states/san_francisco"}, {"ts": "0.0","uuid": "7c786032-0cbd-41bb-9502-00661cb1b96b","partitionpath": "americas/united_states/san_francisco"}]
scala> val delDF = spark.read.json(spark.sparkContext.parallelize(deletes,2))
warning: one deprecation (since 2.12.0)
warning: one deprecation (since 2.2.0)
warning: two deprecations in total; for details, enable `:setting -deprecation' or `:replay -deprecation'
delDF: org.apache.spark.sql.DataFrame = [partitionpath: string, ts: string ... 1 more field]
scala> delDF.write.format("hudi").
| options(getQuickstartWriteConfigs).
| option(OPERATION_OPT_KEY, "delete").
| option(PRECOMBINE_FIELD_OPT_KEY, "ts").
| option(RECORDKEY_FIELD_OPT_KEY, "uuid").
| option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
| option(TABLE_NAME, table).
| mode(Append).
| save(path)
warning: one deprecation; for details, enable `:setting -deprecation' or `:replay -deprecation'
22/07/24 18:33:18 WARN config.DFSPropertiesConfiguration: Cannot find HUDI_CONF_DIR, please set it as the dir of hudi-defaults.conf
22/07/24 18:33:18 WARN config.DFSPropertiesConfiguration: Properties file file:/etc/hudi/conf/hudi-defaults.conf not found. Ignoring to load props file
scala> spark.read.format("hudi").load(path).registerTempTable("trips_del_view")
warning: one deprecation (since 2.0.0); for details, enable `:setting -deprecation' or `:replay -deprecation'
scala> spark.sql("select uuid,partitionpath from trips_del_view").count
res11: Long = 7
This experiment reference Hudi official document Quich start guide.